|
Remember if you want to print from this section,
do it by 'Print Selection' in the Print dialogue box in the file menu.
Click on the link below to navigate to another part of the User Guide:
1. Introduction
Purpose of this guide
The purpose of this basic user guide is to provide a straightforward presentation of the
European Community Household Panel (ECHP) dataset for new users and to provide a reference
to more detailed information for experienced users. The guide is intended to give the new
user sufficient information to begin working with the ECHP data. For more experienced
users, the guide provides, in a compact format, references to the appropriate Eurostat
documentation dealing with key data issues.
Overview of the ECHP
The ECHP is a harmonised cross-national longitudinal survey focusing on household income
and living conditions. It also includes items on health, education, housing, migration,
demographics and employment characteristics.
The survey runs from 1994 to 2001. In the first wave (1994) a sample of some 60,500
households i.e. approximately 130,000 adults aged 16 years and over were interviewed
across 12 member states (Belgium, Denmark, Germany, Greece, Spain, France, Italy, Ireland,
Luxembourg, The Netherlands, Portugal, the United-Kingdom). In wave 2 (1995) Austria, then
Finland in wave 3 (1996) joined the ECHP. From Wave 4 (1997) Sweden provides
cross-sectional data in the UDB format derived from its National Survey on Living
conditions.
For most of the countries the surveys were carried out using the harmonised ECHP
questionnaire. For some countries the institutes in charge of the production of the ECHP
converted national data surveys into ECHP format to replace the ECHP from 1997 onwards. In
Germany and the United Kingdom, the derived national data was provided from 1994 to 2001.
The details of these variations across countries and national surveys are given in Table
1. Care is needed in analysing the converted data for these countries, as some information
might not have been collected in the national surveys so that they will appear as missing
in the ECHP. In other cases, variables that were not collected in the national survey were
imputed based on similar variables.
Table 1: Nature of ECHP data by country and year (Harmonised
original ECHP data and data derived from existing national sources)
Countries |
Full ECHP Data Format |
ECHP Data FormatDerived from
National Surveys |
| Belgium*, Denmark,France, Greece, Ireland, Italy, the Netherlands*, Spain,
Portugal |
1994-2001
|
- |
| Austria |
1995-2001
|
- |
| Finland |
1996-2001 |
- |
| Germany |
1994-1996
|
1994-2001 (SOEP) |
| Luxembourg |
1994-1996
|
1997-2001 (PSELL) |
| United-Kingdom |
1994-1996 |
1994-2001 (BHPS) |
| Sweden |
- |
1997-2001 (SLCS)
(Cross-sectional data only) |
* The ECHP data for Belgium and the Netherlands come from a modification of existing
national panels to meet the ECHP requirements. These are listed in the first column above
because this system was in place from the beginning of the ECHP and national
questionnaires were substantially modified to meet the ECHP requirements.
From the Production Data Base to the User Data
Base
Within each country represented in the ECHP the surveys were carried out by the
"National Data Collection Units", "NDUs" that are either the National
Statistical Institutes or research centres. The results of the interviews were then
transmitted to Eurostat using a format very close to the questionnaire. These datasets
were checked and formatted by Eurostat as the 'Production Data Base' (PDB). The PDB which
is only available to the "NDU's" is then used by Eurostat for weighting,
imputation and construction of the 'User Data Base' (UDB). The UDB is the standardised,
anonymised and more user-friendly user version of the ECHP data made available to
researchers under an ECHP research contract signed with Eurostat.
|
|
|
|
 |
Characteristics of the ECHP dataset
Three central features of the ECHP make this dataset a valuable source of information for
researchers.
The first feature is the multidimensional character of the topics covered. The ECHP
provides microdata on a wide range of topics at the level of individual and household:
income, social life, housing condition, health, education, employment, training, and so
on.
The second feature is the cross-national comparability of the data. The ECHP (apart
from those countries using data derived from national sources, as noted above) is a
harmonised and comparable dataset across countries. This has been achieved through the
implementation of common procedures at all stages from the design of a harmonised
questionnaire, harmonised definitions and sampling requirements.
The third and final main feature of the ECHP is its longitudinal nature. Individuals
who were members of a household in the first wave ('sample persons') are followed over
time allowing researchers to examine how their circumstances change over time. As such,
the ECHP provides information on relationships and transitions over time at the micro
level.
Data access
The ECHP dataset is available through one of the Eurostat Datashops. Contact details for
the Datashops and further details on the requirements for access to the data can be found
on the following web site: http://forum.europa.eu.int/irc/dsis/echpanel/info/data/information.html.
Set-up programs
There are two ways Eurostat distributes the dataset. The first one consists of a CD-ROM
that includes the documentation of the ECHP UDB as well as a self-extracting file to
produce the dataset. The second way is by "downloading" the files through
Internet connection.
In both cases Eurostat supplies the dataset files in a "comma separated
variable" (CSV) format. A file in CSV format is a plain text file where all values
(text, numbers...) are separated by commas and, in the case of string (alpha) variables,
enclosed with double quotes. Because they are not application-specific, CSV files can be
opened on any computer system and by most applications.
However, the files will have to be converted into a readable format before the data can
be analysed using statistical packages such as SAS, STATA or SPSS. Some programs are
available online for this purpose [Reference to EPUNet website where SPSS and Eurostat's
SAS programmes will be available].
2. Documentation
Eurostat has prepared a number of documents providing details about the content and
character of the ECHP data files, and background on survey methodology. The key documents
are sent to users who obtain the data on CD ROM on the CD itself.
They are also available on the CIRCA library web site page dedicated to ECHP http://forum.europa.eu.int/Public/irc/dsis/echpanel/library.
Because of the large number of these documents we can't fully describe all of them here
but Figure 1 outlines the structure of the CIRCA website in order to facilitate a search
for a specific document. In addition, Annex A provides a comprehensive list of all
documents available on this website following the same structure as on the CIRCA web site.
Figure 1: Organisation of the CIRCA web site on ECHP
documentation [needs to be updated]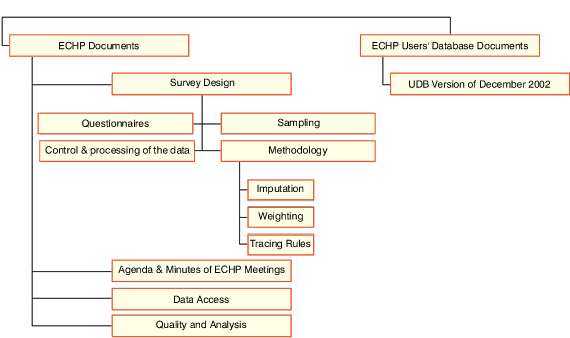
Table 2 outlines the content of some of the key documents likely to be of use to ECHP
analysts.
Table 2: Key ECHP documentation
Document Name |
Description of the content |
PAN 15 |
The variable list and codebook for the household and personal register
records as well as for the household and personal questionnaire records for Wave 1 (1994).
|
PAN 30 |
As above but for wave 2 (1995) |
PAN 65 |
As above but for wave 3 (1996) |
PAN 81 |
As above but for wave 4 (1997) |
PAN 97 |
As above but for wave 5 (1998) |
PAN 112 |
As above but for wave 6 (1999) |
PAN 151 |
As above but for wave 7 (2000) |
PAN 159 |
As above but for wave 8 (2001) |
PAN 165 |
Describes the weighting procedure that has been implemented for
calculating individuals and households weights without describing however how these
weights have to be used |
PAN 166
|
Describes the variables (data dictionary, code book, and differences
between countries and waves). The document is divided between the Household file and the
Personal file, themselves divided into categories such as General Information,
Demographic, Income and so on. |
PAN 167 |
Describes the conversion of the variables from the PDB questions to
the UDB variable format for the household file, personal file as well as link fixed
variables and link wave specific variables (household and personal) |
PAN 168 |
Presents the ECHP history as well as describing the dataset (the
various files), the contractual arrangements and the related documents (Doc PAN 164, PAN
165 etc…) and the contacts for the National Data Collection Units and Eurostat |
|
|
|
|
|
3. Structure of the ECHP User
Database
This section provides an outline of the content of the ECHP User Database (UDB) files, as
covered in more detail in the document PAN168. The UDB includes several files that are
wave-specific (a "register file" a "relationship file", a
"household file" and finally a "personal file") and two files cover
all the waves (the "country file" and the "longitudinal link file").
Annex B provides a list of the variables included in each file.
3.1 Country File
This file contains the following information for each wave and country:
- Population figures (number of private households in the country, number of
persons living in private households, number of persons aged at least sixteen and living
in private households) which can be used to rescale the weight to gross-up the results to
population figures.
- Purchasing power parities (PPP) and Purchasing Power Standards (PPS): PPPs
are a fictitious currency exchange rate, which eliminate the impact of price level
differences; 1 PPS will thus buy a comparable basket of goods and services in each country
(they are scaled at EU level, which is why PPS can be thought of as the Euro in real
terms).
- Exchange rates figures to convert national currencies to ECU/EURO. The
country file contains also the fixed exchange rates for the 'Eurozone' countries (after
01.01.1999).
3.2 Longitudinal Link File
This file contains a record for every person that ever appeared in the ECHP. The first
section contains information (gender, year of birth…) that remains constant over
time. The second section, which is repeated in each wave, contains all the information
(household identifier, household size…) required to rebuild the "longitudinal
status" of the person from the beginning to the end of the panel, derived from the
personal and household register files. Each person receives an identification number (PID)
that is fixed across all waves. Note that the PID is unique only within country: when
several countries are being analysed, the country code must also be used to create a truly
'unique' identifier. [Link to this point in Register of Queries and Solutions].
|
|
|
|
|
3.3 Register File See variables...
This file covers all persons currently living in households with a completed household
interview. There is one register file for each wave of data. Principally the information
available for each person is the household and personal identifier, the weights, year and
month of birth, age and gender.
3.4 Relationship File See variables...
This file records the relationship between each pair of persons in the same household.
There is a separate relationship file for each wave. Its records have the format
"person X has relationship R with person Y". The following rule is used in
specifying the variables corresponding to X, and Y:
If the relationship is between an ascendant and a descendant (such as parent and child),
'R' (variable 'Relation') always specifies the descendant side of the relationship (e.g.
the child, grandchild etc.). Variable PID1 is the fixed identification number (PID) of the
ascendant, and variable PID2 is the fixed identification number (PID) of the descendant.
In the relationship file individuals are identified in terms of their fixed PIDs, so that
the consistency and evolution of relationships can be traced over waves.
3.5 Household File See
variables...
This file contains one record for each household with a completed household interview.
The data in the household file is grouped into 7 sections as follows:
- HG: General information
- HD: Demographic information
- HI: Household income
- HF: Household financial situation
- HA: Accommodation
- HB: Durables
- HL: Children
3.6 Personal File See
variables...
This file contains one record for each adult with a completed personal interview. The
information is grouped into 13 sections as followed:
- PG: General information
- PD: Demographic information
- PE: Employment
- PU: Unemployment
- PS: Search for a job
- PJ: Previous job
- PC: Calendar of activities
- PI: Income
- PT: Training and Education
- PH: Health
- PR: Social relations
- PM: Migration
- PK: Satisfaction with various aspects of life
3.7 Variables Used for Matching Files
The following diagram shows how the UDB files are linked in terms of the identifiers or ID
numbers. It shows, for example, that in order to 'attach' information on the household
file to a particular individual, you would need to match the household file to the
personal file using Wave, Country and HID.
Figure 2: Examples of Identifiers Used in Linking Files
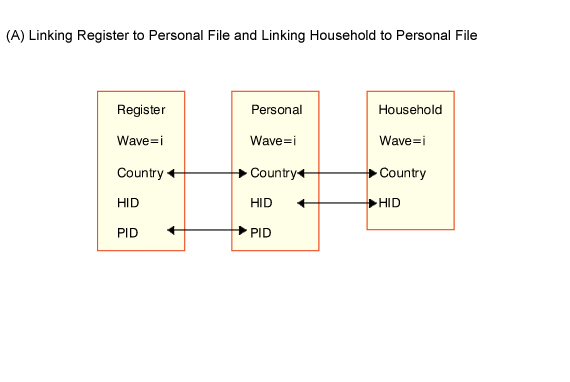
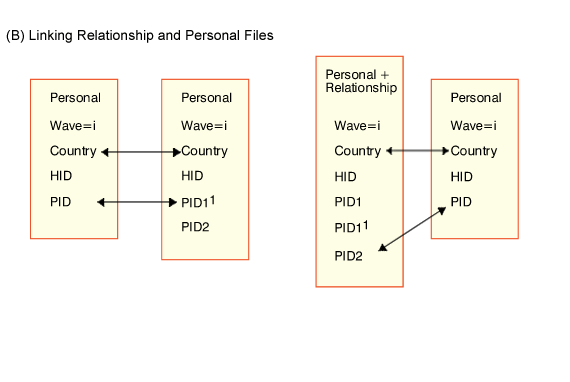
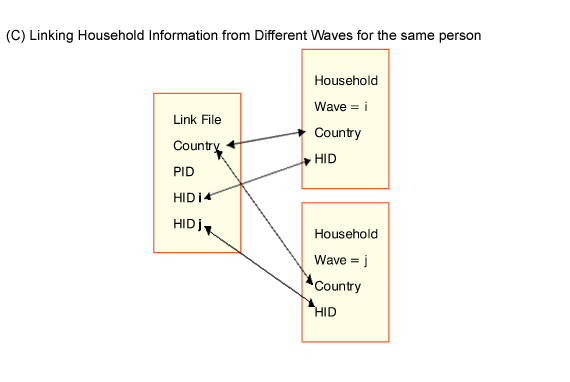
3.8 Number of observations in each file and wave
The following table gives an indication of the number of cases available for
cross-sectional analysis in each wave. It shows the number of cases in each of the UDB
data files.
Table 3: Number of observations in each file and wave
|
Link File |
Household |
Register |
Personal |
Wave 1 |
N.A. |
71,367 |
198,070 |
149,306 |
Wave 2 |
N.A. |
73,715 |
204,060 |
156,063 |
Wave 3 |
N.A. |
74,746 |
205,432 |
157,536 |
Wave 4 |
N.A. |
68,788 |
186,987 |
143,935 |
Wave 5 |
N.A. |
66,097 |
177,434 |
136,238 |
| Wave 6 |
N.A. |
64,285 |
171,093 |
131,372 |
| Wave 7 |
N.A. |
61,330 |
161,735 |
124,937 |
| Wave 8 |
N.A. |
59,852 |
156,606 |
121,122 |
All waves |
277,240 |
N.A. |
N.A. |
N.A. |
Note: Data files for Waves 1-3 include the data from national sources for Germany and
the UK, as well as the data from the original ECHP.
3.9 Number of cases available for Longitudinal Analysis
The following table gives an indication of the number of cases available longitudinal
analysis. It shows the number of cases for which information is available in all of the
indicated waves1. It is clear that sample attrition has reduced the number of
cases available for longitudinal analysis. [Link to Doc Pan on
Attrition].
1Note that the figures include both the ECHP and national samples for
Germany and the UK (1994-96) and Luxembourg (1995-96).
Table 4: Number of cases available for selected longitudinal
analyses
|
Number Persons
(all ages) |
Number of Personal Interviews |
Wave 1-2 |
179,464 |
132,220 |
| Wave 2-3 |
187,573 |
139,594 |
| Wave 1,2,3,4,5,6,7 |
99,516 |
70,966 |
| Wave 1,2,3,4,5,6,7,8 |
92,350 |
65,622 |
4. Weights
In the ECHP UDB files, weights are available for households and persons. These weights are
calculated taking into account the sample design and characteristics of persons and
households. The weights are calibrated to reflect the structure of the population.
The purpose of this section is to describe briefly the various weights and their
appropriate use. For a detailed description of the weighting procedures that have been
implemented for calculating weights in the ECHP, see PAN 165.
Table 3 describes the weights provided for each wave and file. There are two types of
weights: the base weight (at individual level only) which would be used for longitudinal
analysis and the cross-sectional weight (at both individual and household level) for use
in cross-sectional analyses.
The base weight is available only for 'sample persons'. In Wave 1 all persons in
interviewed households are considered as 'sample persons' - eligible to be followed from
one wave of the panel to the next. In the following waves, new entrants to existing
households are defined as 'non-sample persons' to distinguish them from those present in
the first wave. These new sample members have a zero base weight, but a non-zero
cross-sectional weight.
Table 4: Weights available in the ECHP UDB
|
Name of the weight variable |
|
File type |
Base weight |
Cross-sectional weight |
| Register |
RG003 |
RG002 |
| Personal |
PG003 |
PG002 |
| Household |
- |
HG004 |
|
1 Under ECHP tracing rules, if a household does not contain any 'sample persons' (for
example, they moved out or died), the household is dropped from the panel.
Register file
Two sets of weights are in the dataset, the base weight and the cross sectional weight.
Children, as well as adults, have a cross-sectional weight and a base weight on the
Register file.
Base weight (RGOO3)
In Wave 1, all 'sample persons' (including children) receive a non-zero base weight
and all persons in the same household share the same weight.
From Wave 2 and onwards the base weights are computed on the basis of the Wave 1 base
weights, modified to take into account attrition between the waves and calibration of the
achieved sample to external control distributions by basic personal and household
characteristics. New members (joining the household after Wave 1) do not have a base
weight assigned.
Cross-sectional weight (RGOO2)
In Wave 1 the cross-sectional weights are identical to the base weights and are equal for
all household members. From Wave 2 and onward households members have the same
cross-sectional weight that is computed as the average of the base weights of all
household members.
Personal file
As for the register file, base weights and cross sectional weights are available in the
dataset.
Base weight (PGOO3)
All 'sample persons' who complete a personal interview (and have a record in the Personal
File) receive a non-zero base weight and 'non-sample persons' receive a zero base weight.
The personal file base weight is derived from the register file base weight and is
adjusted to take account of variations in response rates on the Personal Questionnaire by
age, gender and other personal characteristics. Therefore, unlike the register file base
weight, the personal file base weight will differ between household members.
From Wave 2 and onwards the same applies, that is, 'sample persons' receive a non-zero
base weight and 'non-sample' persons receive a zero base weight.
Cross-sectional weight (PGOO2)
In Wave 1 the cross-sectional weight is identical to the base weight.
From Wave 2 and onward households members have the same cross-sectional weight that is
computed as the average of the base weights of the interviewed household members.
Household file
In the household file across all waves there is only one weight: the cross- sectional
weight. By definition, the base weight cannot apply to households, as households are not
stable in composition across time.
Population scaling
The weights in the household and personal file (as well as the register file) have been
rescaled so that the mean of the weight within country is equal to one. For the purpose of
some analysis one might wish to scale results to population size and to do so we can use a
grossing factor. This grossing factor is constructed as the ratio of two components, N/n.
The numerator (N) is the population size analysed - that is the country total population
(persons for the register file, households for the household file) or the population aged
16 and over (for the personal file). The denominator (n) is the sample size of the
population analysed, that is, the number of cases in the register, household or personal
file, as appropriate. Information on total population sizes (persons, households, persons
age 16 and over) can be found in the country file for each wave.
Longitudinal analysis,
cross-sectional analysis and appropriate weight
By definition with longitudinal analysis we are only concerned with persons present in a
number of consecutive waves that would require the use of a specific weight. Eurostat does
not supply in the ECHP dataset such a longitudinal weight for each subset of waves that
might be analysed. However the base weight (RG003 or PG003) is available for 'sample
persons' who were present in the panel in earlier waves. The appropriate weight to use for
longitudinal analysis, then, is the base weight of the last wave analysed. So, for
instance, to analyse employment information from the personal questionnaires for
1994-1999, PG003 from 1999 would be used.
On the other hand, if the analyst is interested in using the data for cross-sectional
purposes, the cross-sectional weight should be used. This weight is available for all
persons present (and personally interviewed, in the case of PG002) in that wave: both
sample persons and non-sample persons.
5. After the ECHP: EU-SILC
As mentioned earlier, the ECHP ran from 1994 to 2001. From 2004 onwards a new instrument
called EU-SILC (Statistics on Income and Living Conditions) will replace it as the central
source of micro-data on household incomes and social exclusion in the EU. EU-SILC will be
organised under a framework Regulation adopted in 2003 by both the EU Council of Ministers
and the European Parliament. Unlike the ECHP, it will therefore be compulsory for all
Member States. Among the EU-15 Member States, 6 have launched EU-SILC as from 2003 on the
basis of informal agreements signed with the Commission (Belgium, Denmark, Greece,
Ireland, Luxembourg and Austria). Apart from Germany, the Netherlands and the UK, the
other Member States will start in 2004 as foreseen in the Regulation; Germany, the
Netherlands and the UK will start in 2005. Depending on the country, accessing and
candidate countries will launch EU-SILC between 2004 and 2007.
The priority with EU-SILC is the provision of quality, timely cross-sectional information
on household incomes and social exclusion. The emphasis is on output harmonisation rather
than input harmonisation: the data may come from different sources in different EU member
states, and countries with highly developed population registers will be encouraged to use
these sources. Notwithstanding the efforts at output harmonisation, harmonisation (which
are formalised in a series of Commission's Regulation to be approved by the
Director-generals of national statistical institutes) the international comparability of
data from EU-SILC will inevitably be diminished compared to the ECHP. EU-SILC is also more
limited in content than the ECHP. The main differences between the ECHP and SILC are:
- Whereas the ECHP was a full panel (with all sample persons from wave 1
followed for the life of the panel) EU-SILC will allow for a rotational design in which an
individual is followed for four years at most. Countries seeking to conduct a full panel
will, however, be allowed to do so.
- The ECHP was based on the use of harmonised questionnaires in all the
participating member states (at least in the first three waves), but SILC allows key data
on individuals to be drawn from registers or other sources where these are available in a
country. This is done to ensure that each country can use what it considers to be its
'best source(s)' for income data, but reduces the degree to which the methodology is
harmonised across countries.
- Much of the detailed information on labour market situation and on
non-monetary indicators of exclusion has been dropped from SILC.
- EU-SILC allows certain income components to be provided only at the
household level: family allowances (including Child Benefit and Lone Parent Allowance),
property income (interest, dividends, rent), housing allowances (such as rent and mortgage
interest supplements) and social assistance payments. In contrast, apart from social
assistance and housing benefits, the ECHP recorded these at the level of the individual
recipient. This means that SILC will lack the kind of data needed for tax-benefit
modelling at the level of the individual or tax unit.
6. Further Information
As noted earlier, Eurostat has produced a large number of detailed documents on the ECHP,
ranging from the 'blueprint' ECHP questionnaires, through documents dealing with
methodological issues, to the agenda and minutes of ECHP meetings. These are available on
the CIRCA website [Link to Circa website] and a list of the
documents is provided in Annex A.
Apart from this User Guide, the Euro-Panel User Network (EPUNet) has a number of other
resources that are likely to be of interest to new and advanced users of the ECHP. [Link to EPUNet website]. The resources include the following:
- Set-up programmes for use in converting the Comma Separated Variable files
issued by Eurostat into formats for use by SPSS [Link to SPSS set-up
programmes], SAS [link to SAS set-up programmes] and
STATA [Link to STATA set-up programmes].
- A register of "Queries and Solutions"
based on the experience of ECHP Users and covering problems and issues arising in the
course of work on the ECHP and, where available, the solutions that have been proposed.
- An e-mail hotline for queries not
covered in the Register of Queries and Solutions.
- Research Familiarisation Sessions for new and advanced users of the ECHP
[Link to web page on Research Familiarisation Sessions].
- Study Visits where researchers from
institutions who do not already have access to the ECHP can come for a period of several
weeks and use the ECHP data for a specific research project.
- A database of programs for computing derived variables which have been used
in previous research using the ECHP. [Link to database of programs
for computing derived variables].
- A database of research and publications based on the ECHP [Link to database web page].
- An annual conference focusing on comparative research using the ECHP [Link to conference web page].
We hope that you have found this guide helpful. We would be glad to receive comments.
We also hope that you will also consider contributing your own queries, solutions,
programs for computing derived variables and research papers to EPUNet. Contact
for contributions. This is a network of ECHP users for
ECHP users and its success depends on your participation.
|
|